V-Ray開発者(Vlado氏)がNVIDIA RTXカードをテスト
レイトレーシングとGPUレンダリングの未来がどうなるか興味があるでしょうか。Vlado氏(V-Ray開発者)のベンチマーク実験で新しいGeForce RTXカード(2018年)がどのようなパフォーマンスを持っているかを見てみましょう。
概要
この記事は、私たちのRTXレイトレーシングに関する記事のフォローアップです。オリジナルのブログ記事を書いた時、GeForce RTXカードは発表されたばかりで、まだ一般製品として発売開始されていなかった為ベンチマーク結果を共有できませんでした。
ついにRTXカードが発売されたので正式に実験結果を共有することができます。GeForce RTX 2080とGeForce RTX 2080 Tiカードの結果は、前世代のGeForce GTX 1080 Tiと同様に、ラインナップ中で上位を示します。
現在リリース中のV-Ray GPUは、新しいRTコアをサポートしていません。しかし新しいカードのCUDAコアを使って動作させる事は可能です。
ベンチマークでは、以下のシーンを使用しました(一部のEvermotionシーンはオリジナルから設定が変更されています):
 ArchInteriors 13, scene 8 ArchInteriors 13, scene 8 |
 White room White room |
 ArchInteriors 13, scene 11 ArchInteriors 13, scene 11 |
 ArchExteriors 25, scene 2 ArchExteriors 25, scene 2 |
 ArchInteriors 33, scene 8 ArchInteriors 33, scene 8 |
 Lake Lavina Lake Lavina |
CUDA パフォーマンス
この最初の一連のテストでは、まだRTコアを使用していない現行V-Ray GPU Next(CUDAバージョン)を使用しました。 RTX 2080とRTX 2080 Tiカードの純粋なCUDAパフォーマンスを測定し、GPUレンダリングで非常に人気のあるGeForce GTX 1080 Tiと比較しました。
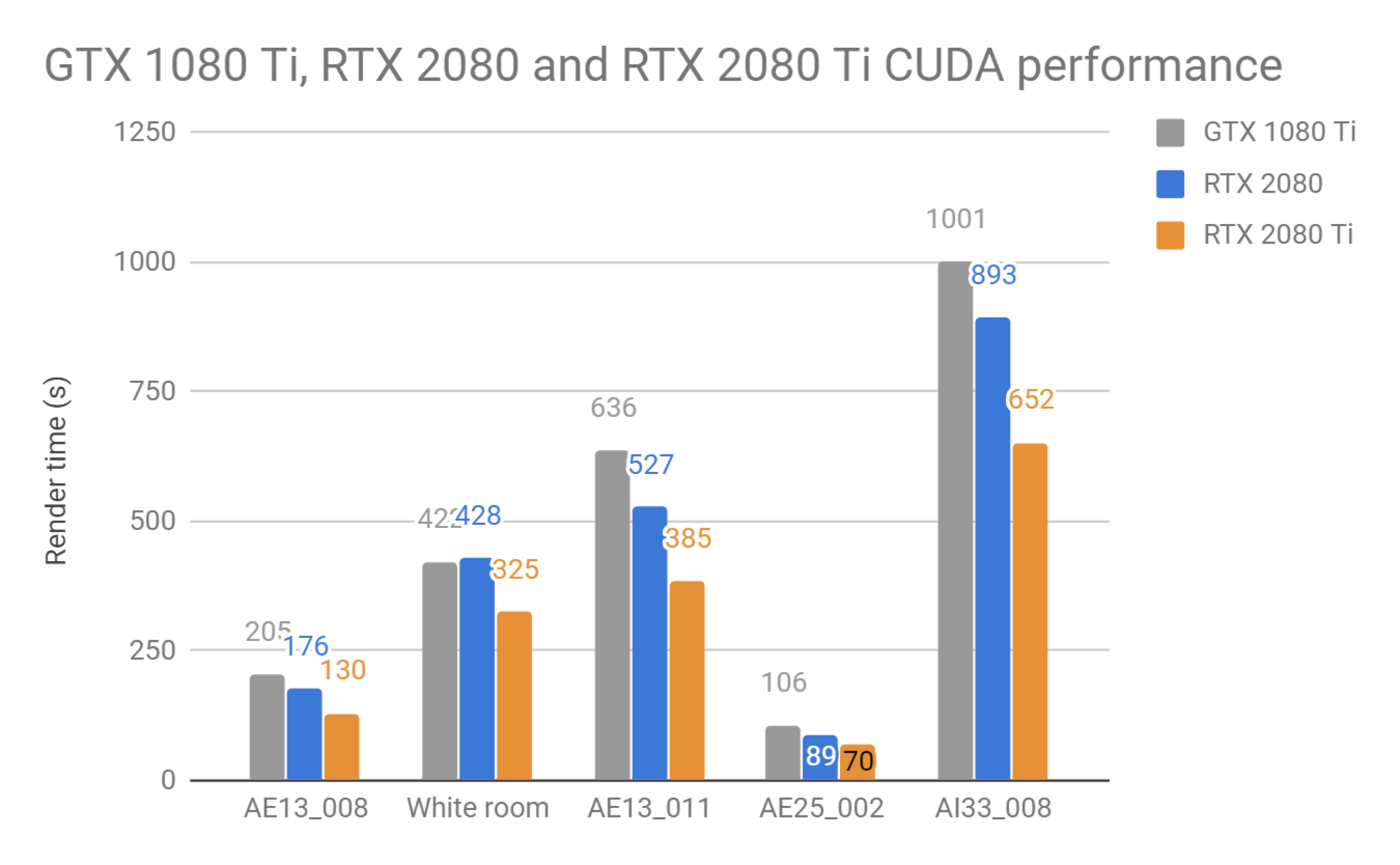
これらのテストからわかるように、RTX 2080とRTX 2080 Tiは、前世代の最高レベル GTX 1080 Tiより高速です。 Tiカードだけを比較すると、Turing世代カードは以前のPascal世代と比較して平均1.52倍の高速化を実現しています。これらはV-Ray Nextの現行バージョンから得られた結果です。
RT Core のパフォーマンス
RT CoreをサポートするV-Rayの公式ビルドはまだ存在しませんが、Chaos Groupでは新しいハードウェアをサポートするV-Ray GPUを作成するためにNVIDIAと1年以上前から協力してテストを行っており、RTコアをサポートするV-Ray RTを既に内部テスト用に作成しています。
内部テスト用V-Ray GPUのRTコアサポートは(現在の所は)OptiXに基づいています。RTコアをサポートするOptiXがまだ公式リリースされていない為、RTサポートするV-Ray GPU も一般公開できませんが、NVIDIA社よりRTコアをサポートするOptiXが公式リリースされると同時に、RTコア対応のV-Ray GPUも公開できる予定です。
以下のテストでは、RTコアサポートするV-Ray GPUの内部ビルドを使用しています。パフォーマンスをさらに向上させることができると期待される多くの改善点がまだある為、最終的なリリースではさらにパフォーマンスが向上する見込みです。
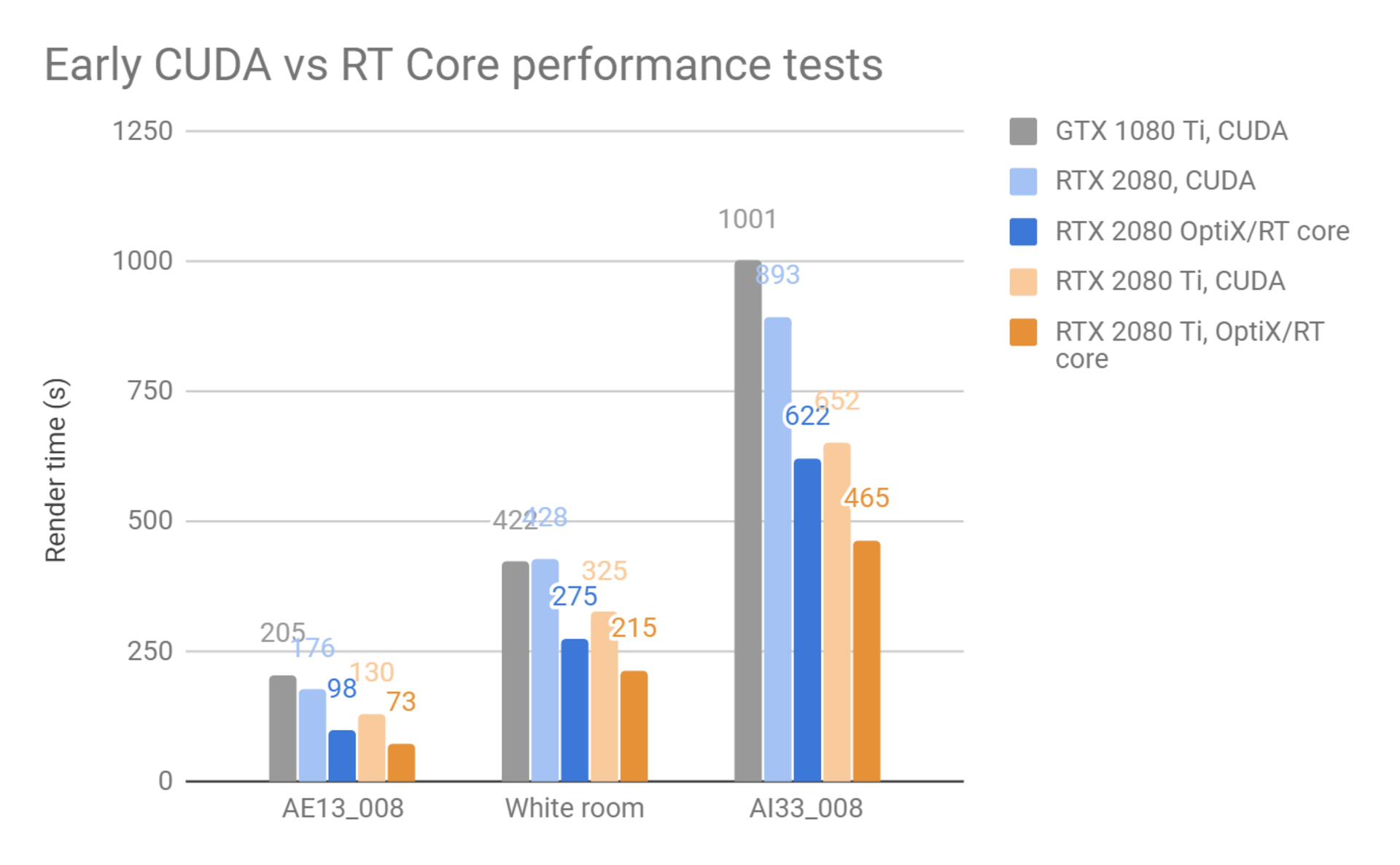
3つのシーンについて、RTコアは純粋なCUDAバージョンと比較して、それぞれ1.78倍、1.53倍、および1.47倍のスピードアップを提供しています。Chaos Groupでは公式リリースに近づくにつれて、これらの結果がより良くなると期待しています。
DXR のパフォーマンス
以下のテストでは、Siggraph 2018で初めて発表したProject Lavinaのリアルタイムレイトレーシングエンジンを使用しました。Project Lavinaは、DirectX 12のDXRレイトレーシング拡張機能に基づいており、リアルタイムレイ・トレーシング用に1から書かれたV-Ray用のレンダリング・エンジンです。LLavinaエンジンは、シャドウ、反射、屈折、GIのバウンスを含む完全なレイトレーシングに基づいており、結果を滑らかにするデノイズ・パスがあります。ラスタライズ処理はまったく関与しないため、純粋にRTコアの速度に大きく影響を受けます。DXRはGTX 1080 Tiのような古いGPU世代ではサポートされていないため、現在使用可能な2つのGeForce RTXカードのみで比較しました。
DXRテストの結果は、HD解像度でフレーム/秒で計測される為、高い数値程良い事を示しています。
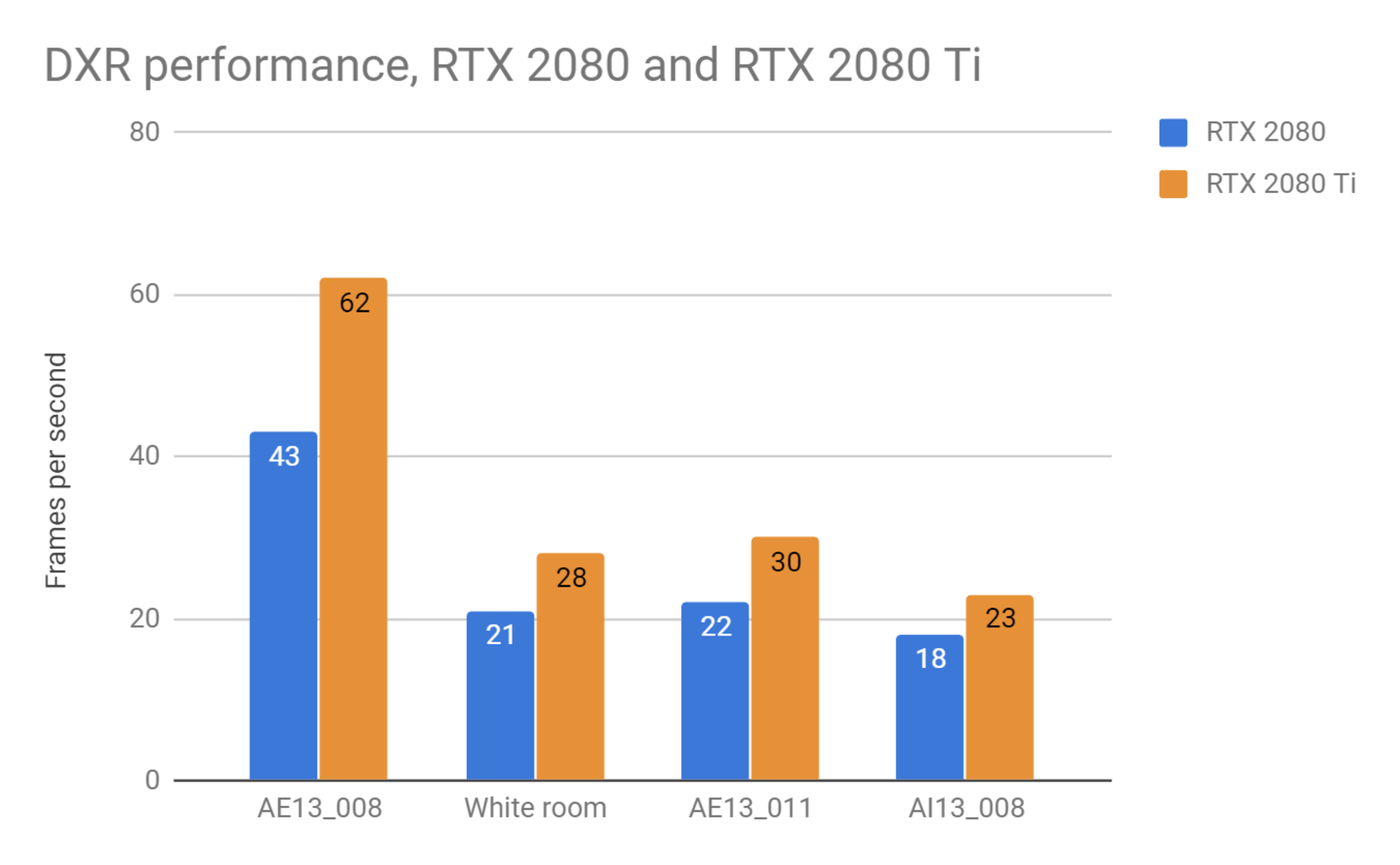
これらの結果から、RTX 2080 TiカードはRTX 2080カードよりも平均1.35倍の性能向上をもたらします。言い換えると、インタラクティブ性に大きな違いが発生します。
NVLink のパフォーマンス
RTコアに加えて新しいRTXカードはNVLinkもサポートしているため、V-Ray GPUは2つのGPU間でメモリを共有することができます。これはレンダリングの速度にもある程度の影響を与えます。このベンチマークでは、NVLinkのレンダリングへの影響を測定することを目指しています。 NVLinkを有効にするには、複数のRTXカードを特別なNVLinkコネクタ(NVLinkブリッジとも呼ばれます)で接続する必要があります。 GeForce RTXカードのコネクタには、物理的にどれだけ離れているかに応じて、3スロット幅と4スロット幅の2種類のコネクタがあります。 Quadro RTXカード用のNVLinkブリッジは、それぞれ2スロットと3スロット幅になります。
GeForce RTXカード用の3スロット幅および4スロット幅NVLinkコネクタ:

4スロット幅のNVLinkコネクタで接続された2つのRTX 2080 Tiカード:

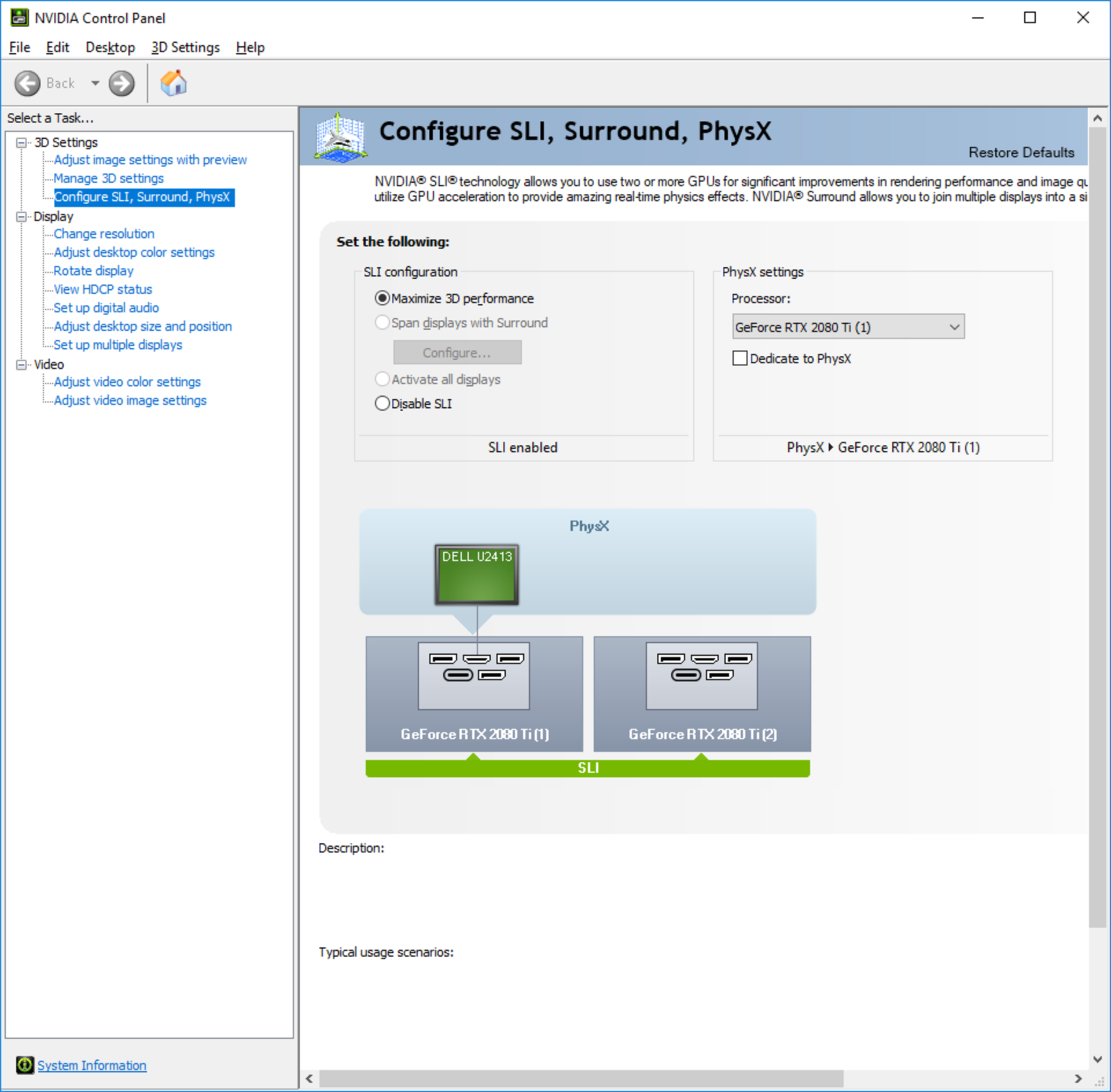
NVLinkをWindows上で動作させるには、NVIDIAコントロールパネルからGeForce RTXカードをSLIモードにする必要があります(これはQuadro RTXカードでは必要ではなく、Linuxでも必要ありません。さらに古いGPUでは推奨されません) WindowsではSLIモードが無効になっているとNVLinkはアクティブになりません。つまり、マザーボードがSLIをサポートしている必要があります。マザーボードがSLIをサポートしていない場合GeForce RTXカードでNVLinkを使用できない事を意味します。またSLIグループでは、プライマリGPUに接続されているモニタだけが動作する事にも注意してください。さらに、2つのGeForce GPUがSLIモードでリンクされている場合、それらのうち少なくとも1つにWindowsが認識できるようにモニタが接続されている必要があります(これはQuadro RTXカードでは必要ではなく、Linuxでも必要ありません)
SLIモードが有効になっているNVIDIAコントロールパネルのスクリーンショット(WindowsではGeForce RTXカードでNVLinkを使用するにはSLIモードが必要です):
NVLinkの速度はRTX 2080とRTX 2080 Tiカードでも異なるため、NVLinkを使用した場合とは異なるパフォーマンスが期待されます。
以下のテストでは、SLIモードと非SLIモードのカードを使用していくつかのシーンをレンダリングし、NVLinkがレンダリング・パフォーマンスに及ぼす影響を確認しました。これらのテストには、現行のCUDAバージョンのV-Ray GPUを使用しました。なお、シーンによってGPU上のRAM量の制限で、SLIなしモード(NVLinkなし)でレンダリングできませんでした。
なおNVLinkを使用すると、GPUレンダリングに使用できるメモリが単純に倍増するわけではありません。 V-Ray GPUはパフォーマンス上の理由から、各GPU上のデータを複製する必要があり、レンダリング時に計算用のスクラッチパッドとして各GPU上にメモリを確保する必要があります。それでも、NVLinkを使うことで、シングルGPUだけで実現するよりもはるかに大きなシーンをレンダリングすることができます。
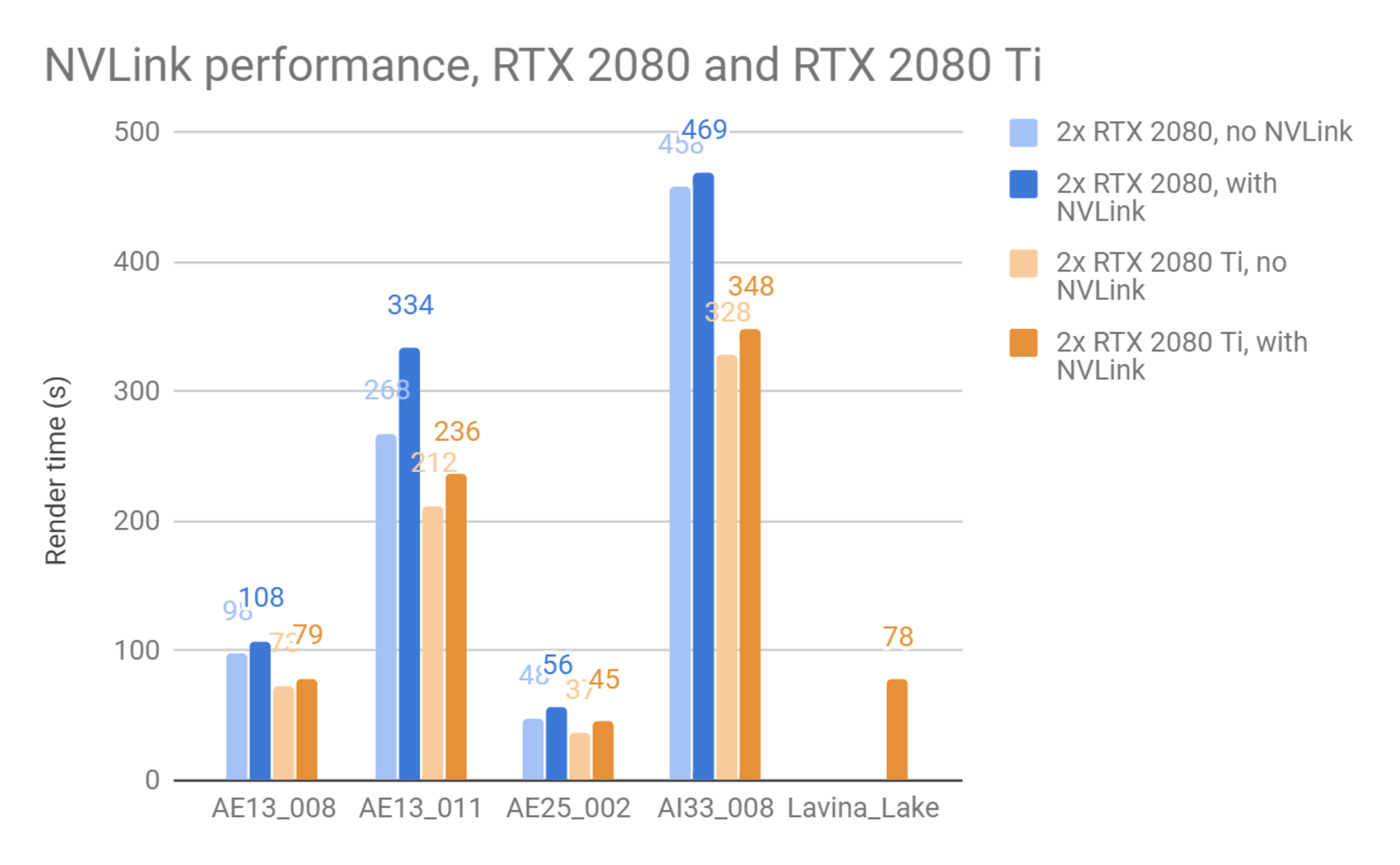
最後のシーンLake Lavinaは、RTX 2080 TiカードのNVLinkモードでのみレンダリング可能でした。他のRTX 2080ではGPUメモリが不十分なためにレンダリングできませんでした。 NVLinkは、NVLink無しと比較して多少のパフォーマンスロスを与えますが、はるかに大きなシーンのレンダリングが可能になるという結果を提供します。殆どの場合、ロスはほんの数パーセントです。 2枚のカード間でのデータの配信方法を微調整することで、将来的にさらに優れたパフォーマンスが得られる可能性があります。
重要なメモ:NVIDIAが提供している通常のGPUメモリレポートAPIはSLIモードでは正しく動作していないようです。(この執筆時点では)つまり、GPUz、MSI Afterburner、nvidia-smiなどのプログラムは、GPUごとに正確なメモリ使用量を示さない可能性があります。私達はこの問題を知っているので、V-Rayフレームバッファで正確なメモリ統計を取得できる様に修正を適用し、そこで実際のGPUメモリ使用量を追跡できます。 NVIDIA社は後日これらの問題を修正する予定です。

V-Ray GPUのアップデート版では正確なGPUメモリ量を示します。(画像の右上 4.2GB Freeの表示)
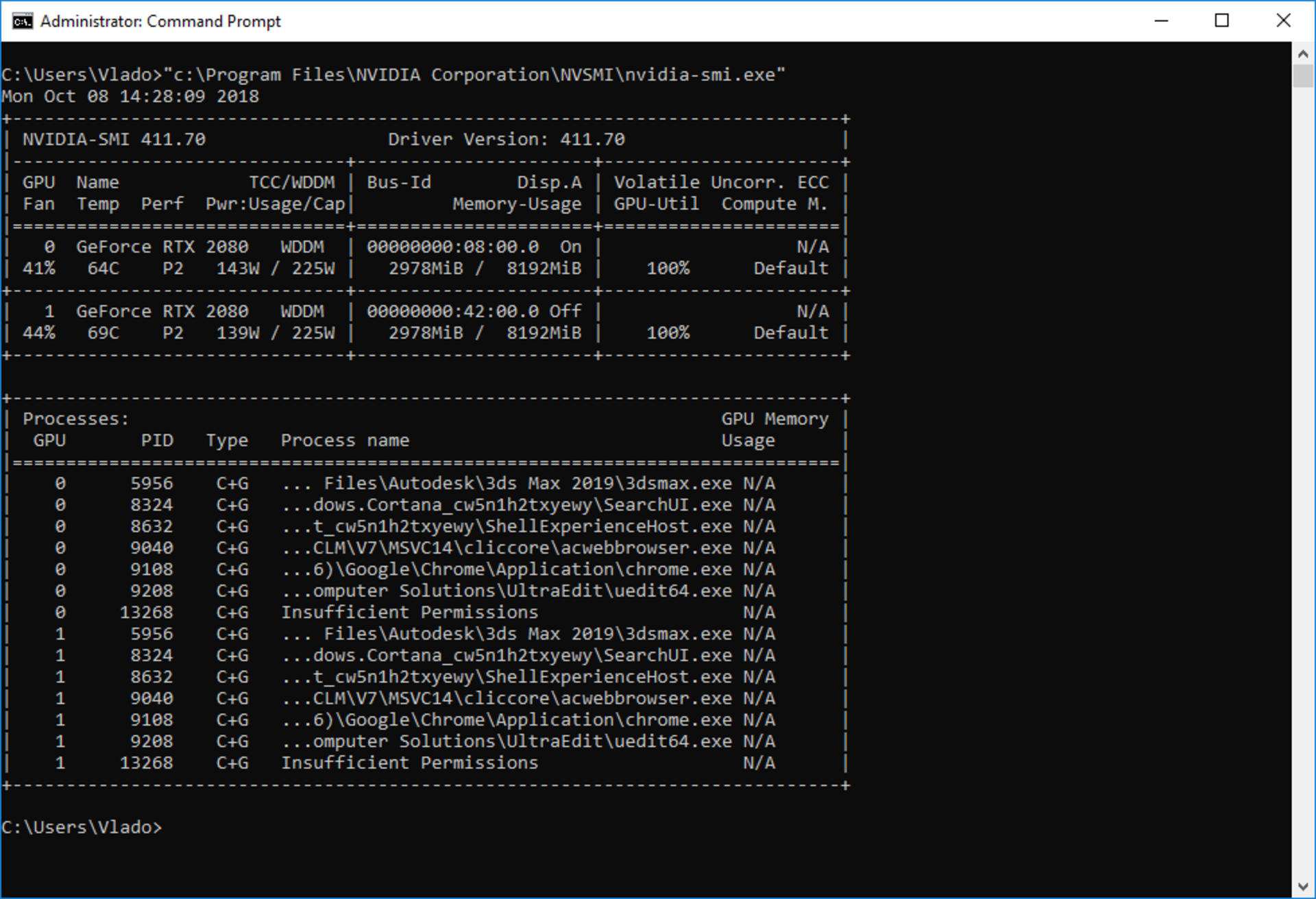
Nvidia-smiツールで両方のカードで同じ量のメモリが使用されているように見えます。(2978MB)

MSI AfterburnerツールもSLIが有効な場合、両方のカードで不正確な同一のメモリ使用量を示します。(2983の表示)
他のシステムツールと比較して、V-Ray GPUの V-Rayフレームバッファでは正確なメモリ使用量を報告します。なおV-Ray GPUは、使用されているメモリとは対照的に、残りの空きGPUメモリを報告します。
まとめ
新しいRTX 2080シリーズは、RT Coreを使用しないCUDA環境でも従来のGTX 1080カードよりも優れたパフォーマンスを提供し、NVLinkを新たに搭載した事でパフォーマンスにほとんど影響を与えずに大きなシーンをレンダリングできる能力を提供します。 RTXカードに組み込まれた新しいRTコアとNVLinkテクノロジは大きな可能性を示していますが、これらを最大限に活用するには、もう少しソフトウェアの最適化と微調整が必要です。
最新記事 by Yamauchi (全て見る)
- V-Ray GPU における AMD GPU サポート - 2026-04-23
- レンダリングを6~10倍早くするTips - 2026-02-09
- V-Ray Maya の DR2 ベータテスト - 2025-09-03

